
Webinar: Establish an information protection and privacy strategy for M365 and beyond

![]()
Automate how you discover, classify, and proactively protect sensitive information Tuesday January 18th, 2022 at 9am PT / 12pm ET / 18:00 CET Information and data protection, done well, presents a long-term opportunity to establish greater trust with customers and unlock employee collaboration and productivity, whilst minimizing security incidents, breaches and regulatory penalties. Most organizations […]
Webinar: AI for Intelligent Migrations

![]()
Use Azure Auto-Classification approaches for finding information of value and accelerated migration to cloud. The key benefits of this approach: Intelligent analysis and migration of large amounts of content Smarter migrations leveraging Azure AI to quickly identify non-compliant or high risk information for remediation Machine models to identify information of value and Records Establish Azure […]
How to best manage access in Microsoft 365

![]()
To enable an effective digital workplace, access needs to be set correctly. Non-sensitive information should be accessible to enable knowledge sharing and reuse, while sensitive information should be restricted and protected. In Microsoft 365 (M365), search results will only show information that you have access to. If access is set wrong, users will not know […]
How Microsoft Teams has been key to growing our business during the Covid-19 pandemic

![]()
The COVID-19 pandemic has been terrible for societies and families around the world, and the required lock-down has negatively impacted many businesses. But the required change has also forced us to rethink how we work and stay connected. We already had the tools available before the pandemic, but not the mindset. During the first six […]
Microsoft Records Management: 8 options for collaborative spaces
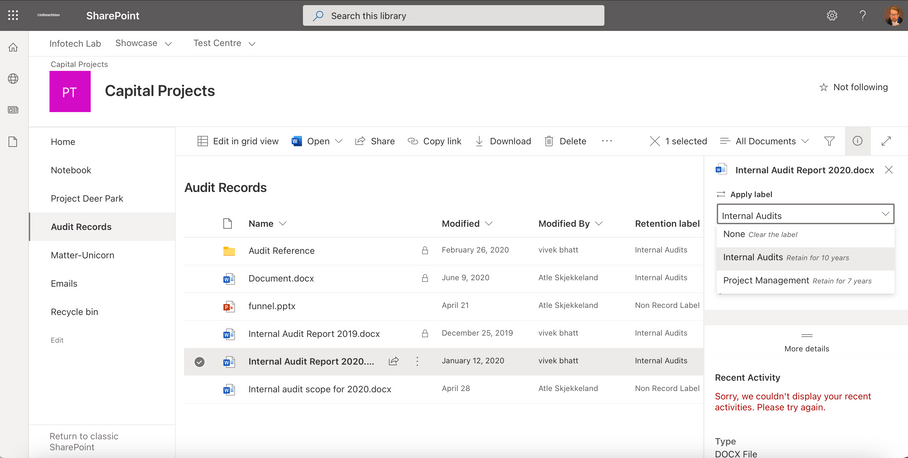
![]()
I have previously written about how to automate M365 Information Governance and Records Management, and I will in this post explain your Microsoft Records Management options for active collaborative spaces. In most scenarios, only the user will know when a collaborative document is final and should be declared as a record. Option 1: Get users […]
Automate Information Governance with M365 AI and Machine Learning
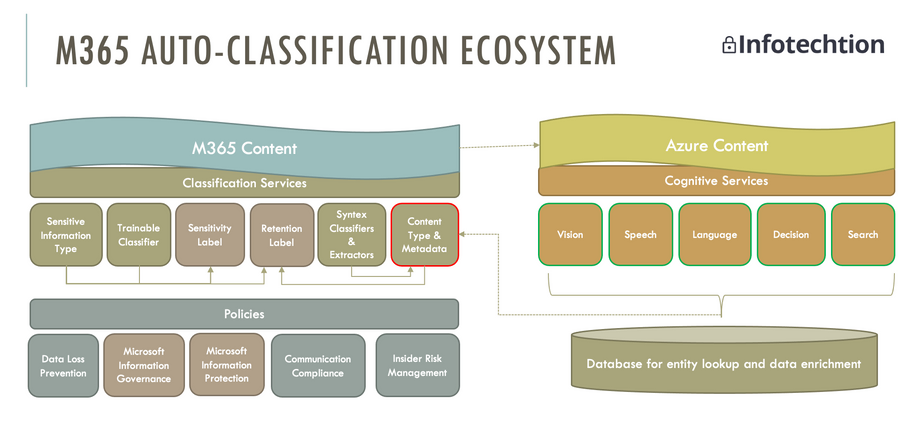
![]()
Earlier this year we did a webinar explaining how to automate information governance and records management in Microsoft 365 (M365), and I will in this blog post explain Sensitive Information Types, Trainable Classifiers, and SharePoint Syntex in more detail. Sensitive Information Types As part of the E3 license, you have Sensitive Information Types with 200+ […]
Retention for Exchange, OneDrive for Business, and SharePoint Online

![]()
An important M365 design decision is to determine if all information should have a lifecycle, not just records. Research by the Compliance Governance & Oversight Council found that in average, 25% of information has business value, 5% is subject to regulatory record keeping requirements, 2% is subject to legal hold, and 68% is redundant, outdated, […]
Automate M365 Information Governance and Records Management
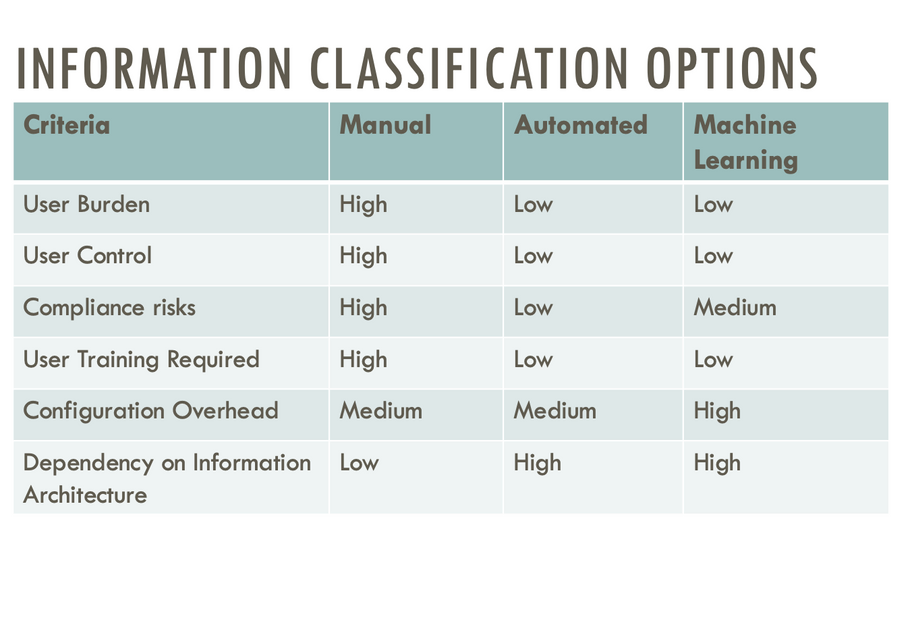
![]()
Oof relying on staff to manually identify and classify important information, e.g. manually apply a M365 record label. By automating M365 Information Governance and Records Management, the burden is then moved from users to the IT/IM/Compliance department for setting up a framework and solution that automate the classification of information. Microsoft 365 (M365) has a […]
From Big Buckets to Records Management in M365

![]()
I have previously written about the value of big bucket retention categories to make it easier for users and machines to select the right retention to ensure compliance with business standards and regulations. I am a big fan of Susan Cisco´s work around big bucket categories, and below are some of her big buckets pros […]
Azure AI for M365 Information Governance and Protection
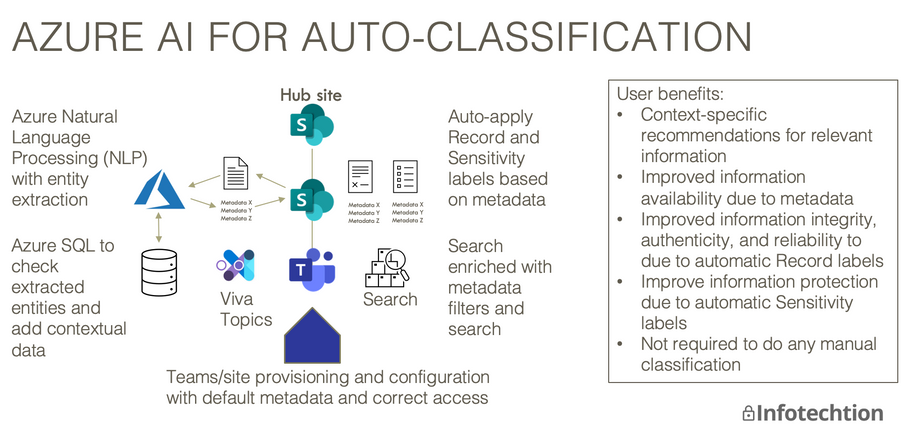
![]()
Microsoft Azure has Cognitive Services available that can be used for auto-classification of files and images. This include the following features: Natural language processing skills include entity recognition, language detection, key phrase extraction, text manipulation, sentiment detection, and PII detection. Image processing skills include Optical Character Recognition (OCR) and identification of visual features, such as […]
