


![]()
I see a lot of excitement among clients about the possibilities of what Copilot can do for their Purview data governance and information protection journeys. It is important not to forget to think about what you can do for Copilot, in anticipation. There are a number of things you can do with your existing investments in E5 licensing and Purview that will improve accuracy and usefulness for all kinds of AI applications. We have discussed in the past how the quality of the content that is put into AI models will improve the quality of the output. This is a step in that direction.
We’re all expecting big things from AI, and we know there are some really good use cases so far, but bulk classification of legacy content into records is going to be a difficult hurdle to get over. Expecting content auto-classification into records categories from Copilot will be challenging because AI models come up short if they:
- Lack context – Document classification for retention often requires a deep understanding of specific regulatory, legal, industry, and organizational contexts. LLMs (language models) are typically trained on a broad corpus and might not be finely tuned to the intricacies of your records management rules.
- Expose data privacy and security: Documents needing retention classification often contain sensitive or confidential information that can be exposed.
- Are not scalable: While LLMs can process large volumes of data, the computational resources and costs required for real-time or batch processing at scale might be substantial.
- Cost resources: Training, fine-tuning, and maintaining LLMs for specific tasks can be costly. Additionally, continuous updates are necessary to ensure compliance with evolving regulations.
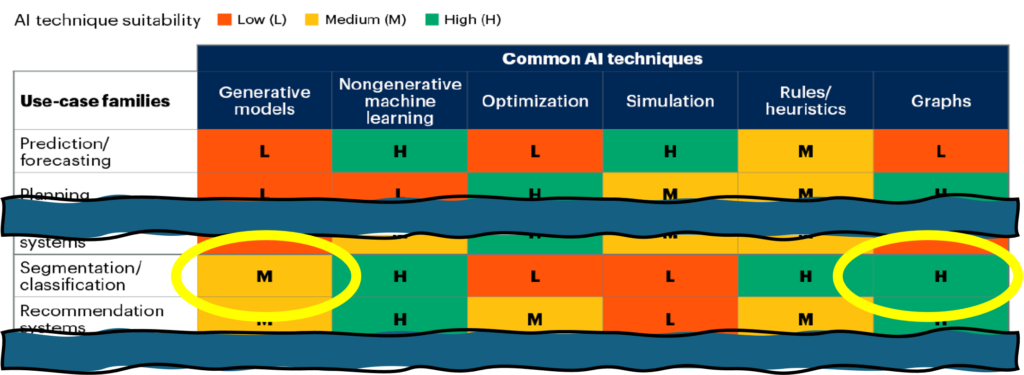
The following excerpted chart from Gartner is a good way to see where various computer assisted use cases benefit from different artificial intelligence capabilities. The expectations for generative technologies to build classifications of content are not as high as we would like, earning only a Medium here on the left. However using rules and heuristics from an auto classification perspective, on the right, is Highly suitable.
An Answer
The rules and heuristics approach, mostly KQL, is a great place to spend time and energy. The rules are fairly simple, often very accurate, and you already own the technologies in Purview to make it happen.
Whether you are examining legacy content on network shared drives in order to capture the valuable stuff or trying to classify content that’s already in SharePoint and teams, leverage the organization that your employees have put on content over the years. Important or voluminous information (both good indicators that they represent records) have been foldered, named, nicknamed, acronymed, numbered, or templated.
These approaches can be used for data governance with record categories, information protection for security classifications, or to help identify valuable or less valuable content to be used in your Copilot language models.
Keywords and Sensitive Information Types are a very powerful way to auto-classify content, but it is important not to think of keywords as a word association. If you want to classify content as agreements, don’t just rely on the word “contract.” It seems like a good first guess, but it will get you a lot of false positives. You might find that “Force Majeure” is much better for finding contracts. Here are some ways to classify content using the tools you may already have:
- Using a specific location (not as a keyword, per se, but as a label on a location) is a good broad way to classify content. If a site location or library contains files of a specific record type, labeling the site will be inherited to all the files in that location.
- Similarly, folders such as “Board of Directors” may exist in several locations but can be found with a single keyword, and it applies to the variety of content in that folder since it is part of the path.
- Often, file path keywords like that have be acronymed or nicknamed the way you would expect. So BOD would be an appropriate additional alternative to “Board of Directors.” If your company has a list of company acronyms, look through that to identify possible keywords.
- Think about the impact that pluralization will have on your chosen keywords. A policy, for example, may well be stored in a folder called policies. So using wild cards in your searches, such as Polic* is quite useful.
- A document title is likely to be found spelled out in the content or body of the document so that is another good place to look. A “Personnel Action Form” will be spelled out in the document and referred to as a PAF in the file name or folder hierarchy.
- Forms can often be found pretty easily and likely represent both records and potential holders of privacy data. A form will often have a form number. Searching for “OMB. No. 1545-“ will find fillable tax forms created by the IRS.
- Sometimes the existence of a number pattern is the best way to classify content. An employee ID number, for example will likely identify content that should be classified as HR data. Number patterns can be found through Sensitive Information Types.
- Remember that the name of the template used to create a document is still a piece of information you can leverage. All the files that came from “specification.dotx” can be classified as specifications.
If content is not important and/or voluminous, it is not likely to have been organized by your knowledge workers. If you go down this path, remember that a consistent approach and less accuracy is better than individual interpretation. In other words, “Don’t let perfection be the enemy of good.” This is a semi-automated process, not just a tool, and human validation and insights are still extremely valuable.
Best for Last: Unlike other file analysis, data protection indexing, or data discovery tools, the same keyword rules you develop here are the same rules you use to classify content from this point going forward.
Now is also a good time to consider a data minimization or data hygiene project to reduce your effort. Throw away, put away, then organize so you don’t spend time analyzing data that should not be there.
Infotechtion helps large organizations understand classify govern and protect their information through Microsoft Purview and Copilot technologies. If you’re interested in learning more, please reach out at contact@infotechtion.com
