


![]()
I recently spoke at a Microsoft Partnership event and thought I’d create a blog post with the same topic. At Infotechtion we’re often tasked with assisting large organizations get control of their data to better protect and govern their sensitive and confidential information. At scale this can be a complex task. In this blog we’re going to explore a tool that we often use in these projects and how we utilize it.
A quick introduction to Sensitivity Information Types
Before we indulge ourselves in the approach and technical jargon, here is a quick summary of Sensitive Information Types(SITs):
- Sensitive Information Type: A classifier used to identify sensitive information such as social security numbers, credit cards, addresses and more.
- Classifiers: There exists many type of classifiers in the M365 portfolio. Trainable classifiers, Exact Data Match classifiers, Sensitive Information Types, Custom classifiers and more. The focus will be on out-of-the-box (OOTB) Sensitive Information Types and custom Sensitive Information Types.
- How do they work?: SITs are pattern based classifiers and looks for content that matches its specified pattern. E.g. how IBAN numbers are built, credit card numbers, and so on.
- Why do we need them?: For many reasons! To protect our sensitive data from exposure, govern our data, to educate and help users
- Where can we use them?: SITs can be used in most areas where we want to do something with information, whether it be Data Loss Prevention policies, Insider Risk Management, Communication Compliance, for auto-labelling, etc.
Where theory meets practice
Let’s look at a hypothetical case:
An organization has used M365 for over a decade without any form of classification or global governance. They now see the risk in continuing this way (larger attack surface, GDPR, outdated information used in AI, just to mention a few) and want to automate both the classification of files and the application of retention label for data lifecycle management needs. To achieve this we’ll in this case use OOTB classifiers and custom classifiers.
An important note here is that most of the OOTB classifiers are created for the English language. If you have an organization that operates in additional languages, or solely in another language, the need for custom classifiers increases.
Firstly, we need to gather requirements
We have the general goal, now we need to gather the requirements and potential wishes to achieve said goal. Does the organization for example have any business requirements, laws to abide by or relevant regulations?. In this case we’ll focus on one selected user story:

Now that we know the requirements, how do we proceed?
We need some data to base our classifiers on. We need to both verify which OOTB classifiers are applicable for this organization and identify areas where we need to build custom ones. One approach is the following:
- Publish labels for manual labelling: Give users the tools to manually categorize and classify content themselves.
- Review the data from manual labelling to use it for automatic labelling: Analyse the manually labelled content for areas to use automation. Use tools such as Content Explorer to review the labelled content, verify the accuracy of OOTB classifiers on your data, and check for areas where you have labelled content where no OOTB classifiers has triggered on the content.
- Create, test and implement classifiers: Identify areas to use custom classifiers where OOTB classifiers is not sufficient enough, test them on production data, verify their accuracy and implement them
Ensure accuracy through pattern recognition
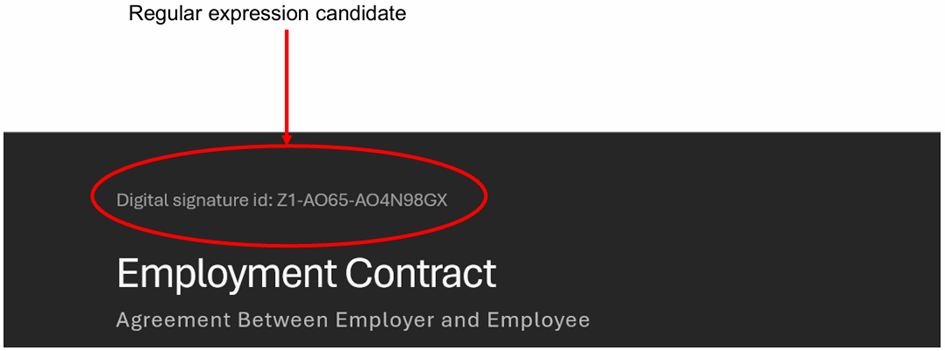
When looking at areas where you need to create custom classifiers, look for common denominators. For example in the user story of the legal department, they digitally signed documents once they were finalized:
Once signed, a signature ID was placed in the header of the document. This ID followed a specific pattern which made it an ideal regular expression candidate for a custom classifier.
Use cases for SITs
Following this approach you will end up with several custom classifiers. For this case the main use-case was for automatic labelling, but SITs has quite a lot of other areas where it can be used as well. You can further develop custom classifiers to scope down the document type that needs protection. Instead of targeting legal documentation generally, you can further narrow the scope using e.g. keyword lists, additional regular expression to for example target Merger & Acquisition documents or Insider information that may need additional protection to prevent data loss and leakage.
Some areas where SITs are applicable to mention a few:
- Data Loss Prevention
- Data Loss Prevention for M365 CoPilot (Public preview)
- Insider Risk Management
- Automatic classification of files and emails
Do you need help to figure out how SITs can help your organization stay compliant and better protect your sensitive and confidential information? Here at Infotechtion, we are experts at implementing Microsoft Purview, ensuring that our customers keep their information safe and their organization compliant with laws and regulations. Please reach out to us at contact@infotechtion.com should you have any questions or need assistance in your work towards better information protection and information management.
